
Le suivi et l'évaluation des programmes dans les populations instables : Expériences avec la base de données de SENS Global du HCR
Par Mélody Tondeur, Caroline Wilkinson, Valérie Gatchell, Tanya Khara et Mark Myatt
Mélody Tondeur est une ancienne consultante du HCR qui travaille maintenant avec le Partenariat canadien pour la santé des femmes et des enfants. Elle est chercheuse et nutritionniste en santé publique, spécialisée dans la malnutrition par carence en micronutriments et les évaluations nutritionnelles en situation d'urgence, avec beaucoup d'expérience de travail sur le terrain en Afrique.
Caroline Wilkinson est la principale responsable de la Nutrition pour le Haut Commissariat des Nations Unies pour les réfugiés (HCR) à Genève et a été pleinement impliquée dans le développement du SENS et de la mise en place des collectes des données mobiles dans les enquêtes SENS du HCR. Auparavant, elle a travaillé pendant 14 ans avec Action Contre la Faim (ACF) dans plusieurs pays et dans son quartier général à Paris.
Valérie Gatchell est l'agent principal de Nutrition et Sécurité Alimentaire pour le HCR à Genève. Elle a 15 ans d’expérience de travail dans les programmes de nutrition avec des organisations non gouvernementales (ONG) et des agences des Nations Unies (ONU) sur le terrain aussi bien qu'aux sièges.
Tanya Khara est une nutritionniste en santé publique et actuellement une des directrices techniques chez ENN. Elle a 20 ans d’expérience dans la programmation de la nutrition dans des contextes de situation d’urgence et de développement, et dans la recherche opérationnelle avec un certain nombre d’ONG, Valid International, l’UNICEF et le Ministère britannique pour le développement international (Department for International Development, DFID).
Mark Myatt est un consultant en épidémiologie et chargé de recherche principal à la Division d’ophtalmologie de l’Institut d’ophtalmologie, à l’University College London. Ses domaines d’expertise incluent la conception de sondages, la nutrition et les maladies infectieuses.
Cette analyse de la base de données SENS du HCR a été rendue possible grâce au financement du Ministère britannique pour le développement international (DFID).
Les données du HCR utilisées dans cet article font partie de l'ensemble de données en santé publique du HCR. Le HCR ne garantit en aucune façon l’exactitude des données ou des informations reproduites d’après les données qu'il fournit et ne peut être tenu pour responsable de toute perte causée en se basant sur l'exactitude ou la fiabilité de ces données.
Lieu : Mondiale
Ce que nous savons : La surveillance et l'évaluation des programmes de nutrition, y compris ceux pour les populations réfugiées, est systématiquement basé sur des enquêtes transversales répétées, en comparant les données initiales et les données finales sur les résultats et les indicateurs de processus.
Qu'apporte cet article : En 2016, une analyse formelle de la base de données des Sondages élargis et standardisés en nutrition (Standardised Expanded Nutrition Surveys, SENS) du Haut Commissariat des Nations unies pour les réfugiés (HCR) a fait apparaître des lacunes dans l’approche actuelle. Les analyses actuelles sont basées sur des enquêtes transversales avant et après qui supposent que les populations étudiées sont stables (naissances et décès en équilibre et faible migration). Cependant, les populations réfugiées sont caractérisées par l'instabilité (en raison d'arrivées et de départs, nouveaux et temporaires) et, par conséquent, une prévalence réduite et une couverture accrue ne peuvent pas nécessairement être attribuées au changement de programme. De nouvelles approches analytiques sont nécessaires pour prendre en compte l'instabilité. L'analyse de données chronologiques montrant des tendances et des exceptions à long terme est idéale, mais des données sont requises sur de longues périodes avec des points régulièrement espacés (ce qui n'est généralement pas possible dans les enquêtes SENS). Une nouvelle procédure est proposée qui consiste à ajuster une courbe LOWESS aux estimations ponctuelles des valeurs des indicateurs (basées sur des données brutes, par exemple la circonférence du bras et le z-score poids-pour-taille) en utilisant les données fournies par une seule enquête comparant les valeurs des personnes exposées et non exposées à une intervention. Des analyses visuelles (diagramme en boîtes) et des analyses statistiques (test de Kruskal Wallis) sont effectuées pour interpréter les résultats. Cette approche a encore des limites et il faut travailler davantage pour tester cette méthode et développer de nouvelles approches.
Contexte
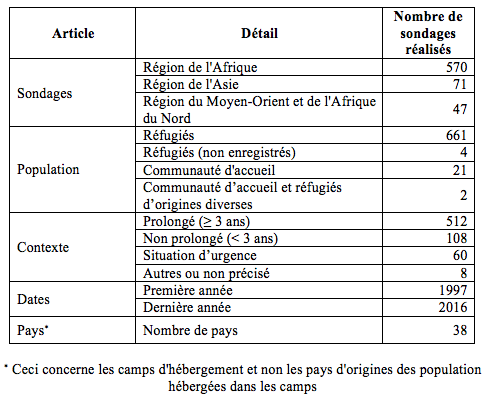
Le HCR et ses partenaires collectent des données sur l'état sanitaire et nutritionnel des réfugiés et des populations apparentées, et sur la couverture des programmes de nutrition depuis de nombreuses années. La méthode la plus fréquemment utilisée est celle des enquêtes transversales répétées qui suivent le modèle SMART. La conception de l’enquête est connue comme la méthode Standardised Expanded Nutrition Survey (SENS). Il s’agit d’un sondage SMART élargi qui recueille des données pour de nombreux indicateurs dans les domaines notamment de la malnutrition aiguë et chronique ; anémie ; diarrhées ; supplémentation en vitamine A ; vaccination ; alimentation du nourrisson et du jeune enfant (IYCF) ; sécurité alimentaire ; eau, assainissement et hygiène (WASH) ; et moustiquaires à insecticide de longue durée1.
Les enquêtes SENS sont utilisées pour l'évaluation des besoins (indicateurs de prévalence) et le suivi et l'évaluation (indicateurs de prévalence et de couverture). Un effort pour collecter systématiquement des rapports d'enquête et des ensembles de données d'enquête à des fins de stockage dans un dépôt central a débuté en 2009. En 2016, la base de données mondiale SENS comprenait 688 rapports d'enquête et ensembles de données correspondants couvrant les populations dans des crises prolongées (≥ 3 ans), des crises non prolongées (< 3 ans) et des situations d'urgence dans 38 pays des régions d'Afrique, d'Asie et du Moyen-Orient, ainsi que de l'Afrique du Nord (voir Tableau 1). La base de données SENS a été largement utilisée pour des analyses ponctuelles. En 2016, une analyse formelle des ensembles de données disponibles a été menée pour la première fois afin d'examiner les tendances des pays et d'éclairer la conception future des enquêtes ainsi que les approches d'analyse des données. Cet article décrit quelques-unes des conclusions de l'analyse, qui suggèrent que les hypothèses traditionnelles sur le suivi et l'évaluation dans les camps de réfugiés peuvent nécessiter une révision.
Tableau 1 : Base de données formée des résultats obtenus par le sondage SENS
Un modèle commun de suivi et d'évaluation
Le suivi et l'évaluation (M&E) des programmes est généralement basé sur des enquêtes transversales répétées qui collectent et rapportent des indicateurs de résultats (par exemple, la prévalence de l’émaciation) et des indicateurs de processus (tels que la couverture de la période de la supplémentation en vitamine A). Les effets saisonniers sont minimisés en utilisant des enquêtes menées au même moment chaque année. Les biais sont maintenus constants en utilisant la même conception d'enquête, de définitions de cas et de méthodes de traitement des données pour toutes les enquêtes.
L’approche la plus simple de surveiller les effets est d’avoir des enquêtes initiales et finales prises au même moment chaque année pour contrôler les effets saisonniers (Graphique 1). L'impact est évalué en tant que changement (c'est-à-dire la différence) de la prévalence entre les données initiales et finales :
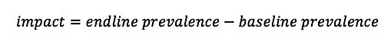
Pour les programmes qui durent plusieurs années, des enquêtes de même conception sont effectuées à la même période de l'année pour chaque année de fonctionnement du programme (Graphique 2). L'impact peut être évalué de la même manière qu'avec les enquêtes initiales et finales :
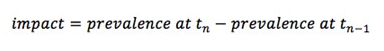
à chaque année, ou comme :
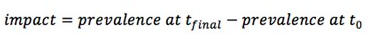
pour toute la durée du programme. Ce type de données peut également être traité comme une série temporelle, comme illustré à la Graphique 3, qui montre la prévalence du retard de croissance dans quatre camps de réfugiés algériens entre 1997 et 2012.
Graphique 1 : Une simple évaluation initialeetfinale
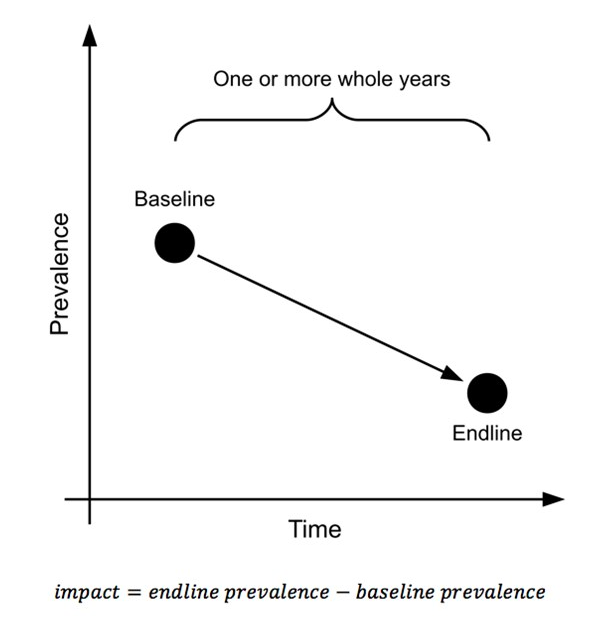
Ceci est uniquement dispnible en anglais - désolé pour tout inconvénient causé
Graphique 2 : Évaluation à partir des données recueillies au fil de plusieurs années
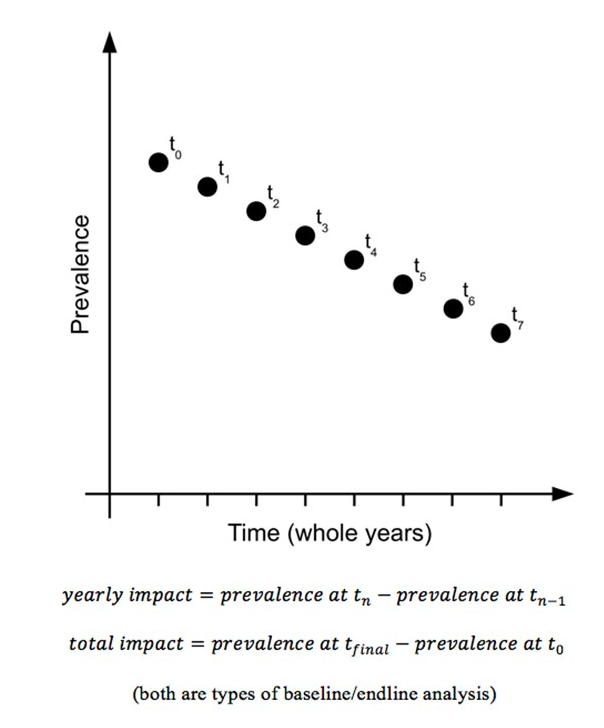
Ceci est uniquement dispnible en anglais - désolé pour tout inconvénient causé
Graphique 3 : Prévalence du retard de croissance dans quatre camps de réfugiés algériens (1997-2012)*
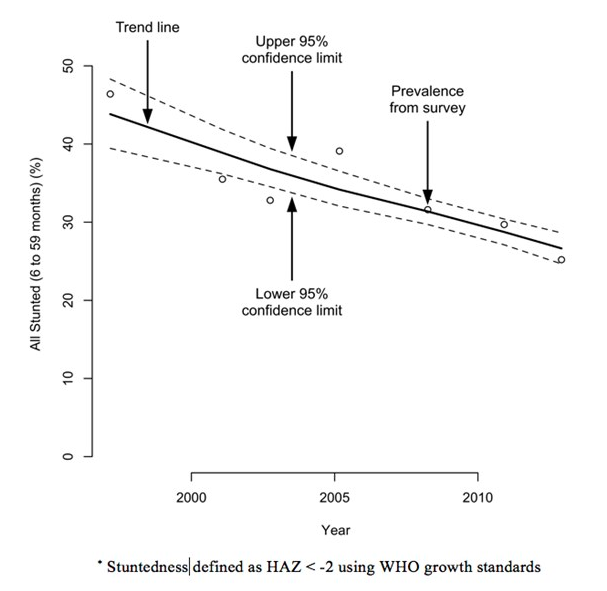
Ceci est uniquement dispnible en anglais - désolé pour tout inconvénient causé
La même approche peut être appliquée pour le processus de surveillance (telles que la surveillance de la couverture du programme) ; la différence étant que le but est de voir la couverture augmenter avec le temps pour atteindre et rester au-dessus d'une norme de couverture minimale critique, comme les normes SPHERE (www.sphereproject.org).
Cette approche du suivi et de l'évaluation du programme émet des hypothèses solides sur la population dans laquelle un programme est exécuté, y compris que la population reste stable pendant la période d'examen. Dans une population stable ou en état stationnaire, la natalité et la mortalité seront à peu près en équilibre, et il y aura des faibles niveaux de migration dans et hors de la zone du programme (Graphique 4). Si ces conditions sont remplies, les réductions observées de la prévalence et les augmentations observées de la couverture peuvent être attribuées aux activités du programme.
Graphique 4 : Représentation sous forme de diagramme de la population dans un état stable oufixe
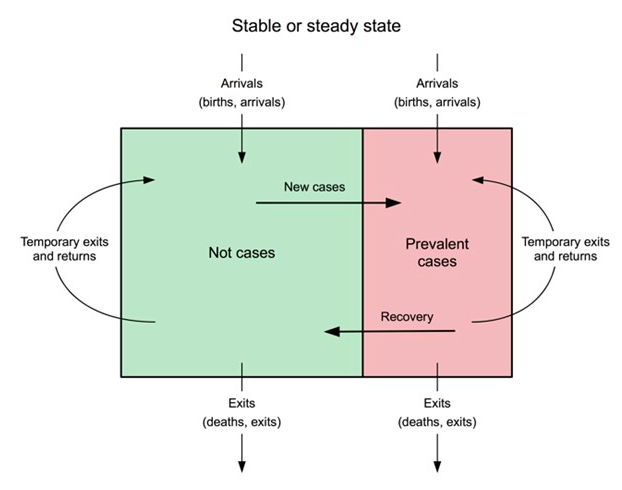
Ceci est uniquement dispnible en anglais - désolé pour tout inconvénient causé
Graphique 5 : Représentation sous forme de diagramme de l’instabilité causée par les arrivées
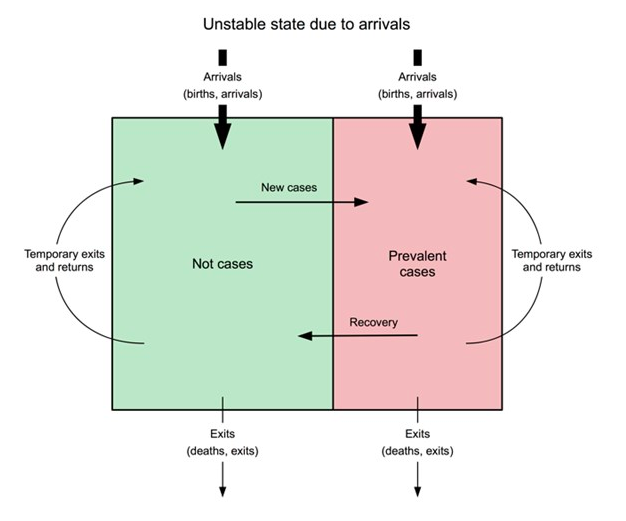
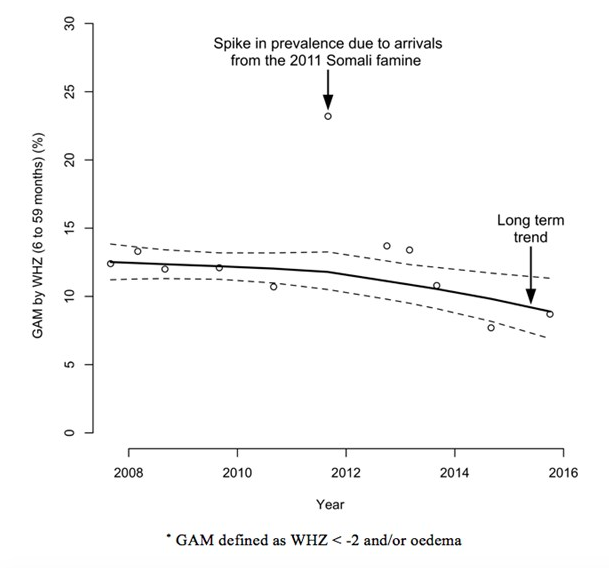
Graphique 6 : Prévalence de la MAG au sein du camp de réfugiés de Dadaab-Dagahaley (2007-2015)*
Ceci est uniquement dispnible en anglais - désolé pour tout inconvénient causé
Graphique 7 : Représentation sous forme de diagramme de l’instabilité causée par les départs
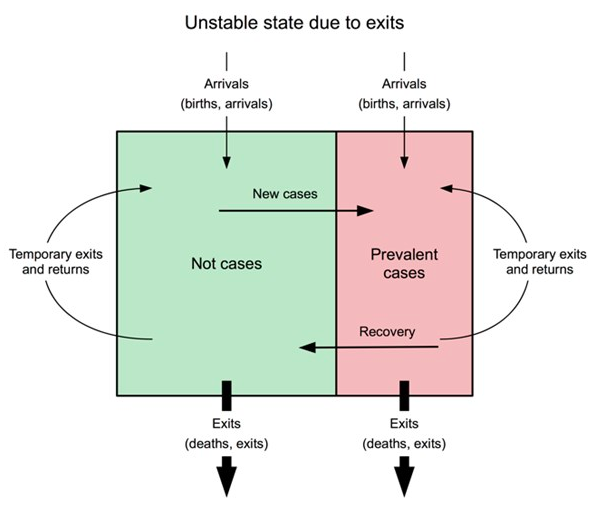
Ceci est uniquement dispnible en anglais - désolé pour tout inconvénient causé
Graphique 8 : Population du camp de réfugiés de Damak au Népal (2005-2014)
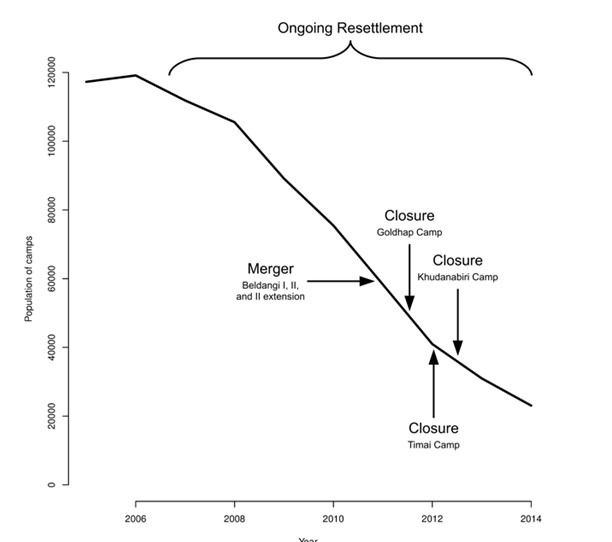
Ceci est uniquement dispnible en anglais - désolé pour tout inconvénient causé
Graphique 9 : Prévalence de la MAG au sein du camp de réfugiés de Damak au Népal (2005-2014)*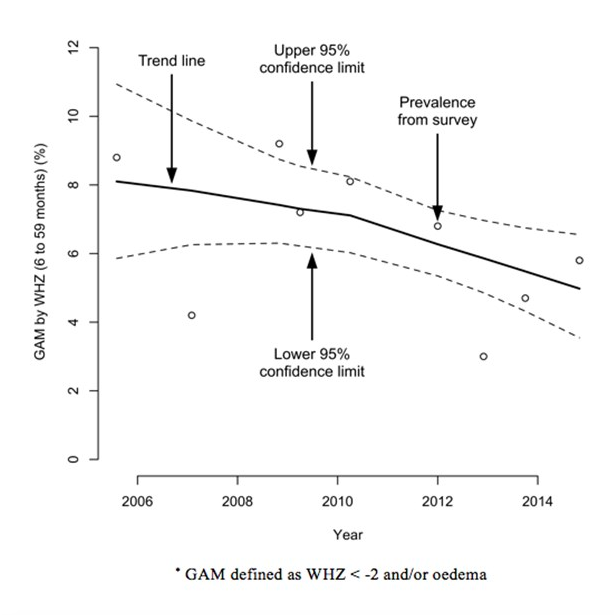
Ceci est uniquement dispnible en anglais - désolé pour tout inconvénient causé
L'instabilité peut également être due à une combinaison de nouvelles arrivées et de nouveaux départs (Graphique 10), entraînant un renouvellement considérable de la population. La Graphique 11 montre le nombre de réfugiés et de demandeurs d'asile par pays d'origine pour le camp de réfugiés de Kakuma dans le nord-ouest du Kenya entre 2004 et 2017. En fonction de la condition des arrivées et des départs, et de l'effet des fluctuations de la population sur la prestation des services, ce « roulement » peut entraîner des changements d'indicateurs par rapport aux tendances à long terme. Les arrivées seront souvent dans de plus mauvaises conditions que la population et/ou les départs du camp existant ; les indicateurs de prévalence auront tendance à augmenter et les indicateurs de couverture à diminuer. Malgré cela, la direction du camp et ses partenaires dans le camp de Kakuma semblent avoir contrôlé la prévalence, et ils semblent être parvenus à atteindre et maintenir des niveaux élevés de couverture des programmes. La Graphique 12 montre la prévalence de MAG, définie comme WHZ <-2 et/ou œdème, et la couverture de la période de six mois de la supplémentation en vitamine A dans le camp de Kakuma dans le nord-ouest du Kenya entre 1997 et 2015.
Graphique 10 : Représentation sous forme de diagramme de l’instabilité causée par les arrivées et les départs
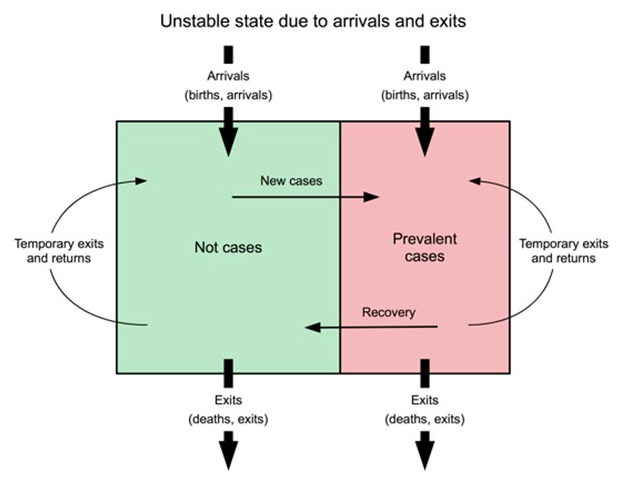
Ceci est uniquement dispnible en anglais - désolé pour tout inconvénient causé
Graphique 11 : Nombre de réfugiés et de demandeurs d’asile en fonction du pays d’origine au sein du camp de réfugiés de Kakuma dans le nord-ouest du Kenya (2004-2017)
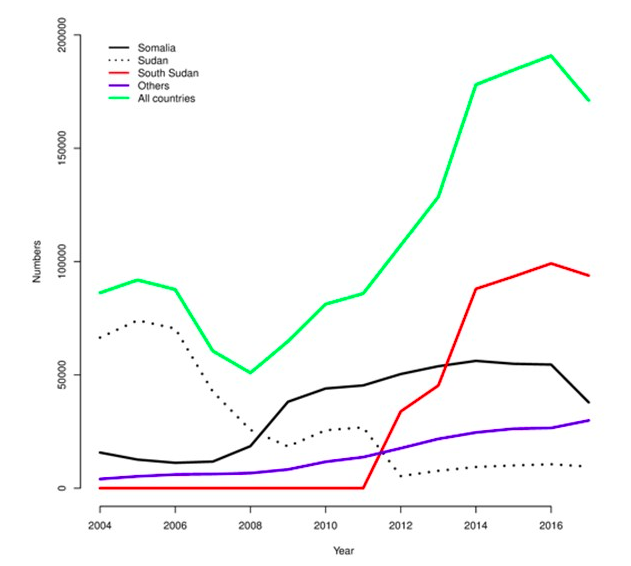
Ceci est uniquement dispnible en anglais - désolé pour tout inconvénient causé
Graphique 12 : Prévalence de la MAG par WHZ et période de couverture d’une durée de six mois du programme de supplémentation en vitamine A au camp de Kakuma dans le nord-ouest du Kenya (1997-2015)*
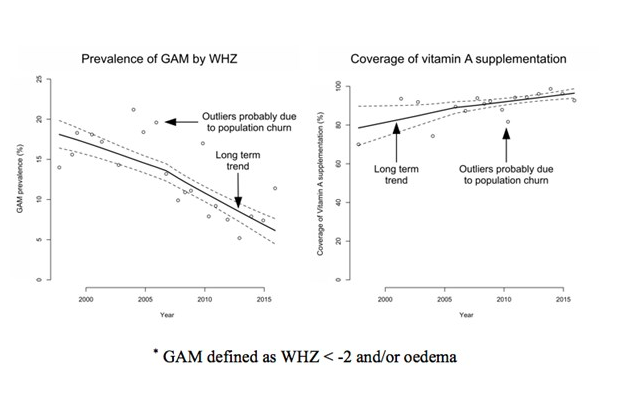
Ceci est uniquement dispnible en anglais - désolé pour tout inconvénient causé
Une source supplémentaire d'instabilité, ce sont les départs et les retours temporaires, dont les conséquences peuvent être difficiles à prévoir (Graphique 13). Dans les cas où des membres d'un ménage quittent le camp pour chercher du travail avec le revenu du ménage qui augmente dans le camp, l'effet sera probablement d'améliorer l'état d'une partie de la population du camp, ce qui peut se traduire par des changements positifs sur les indicateurs de résultats. Dans d'autres cas, les départs peuvent être rentrés chez eux mais sont ensuite revenus au camp après avoir fui la dégradation de la sécurité. Dans ce cas, il peut y avoir des changements négatifs sur les indicateurs de résultats. On sait que des départs et des retours temporaires ont lieu dans tous ou presque tous les camps de réfugiés. Les chiffres impliqués sont cependant extrêmement difficiles à surveiller.
En examinant la base de données SENS, on pensait à l'origine que le modèle données initiales/finales s'appliquerait. Il est devenu évident au cours de l'analyse et de l'interprétation des données qu'en raison de l'instabilité démographique, ce modèle ne s'appliquerait pas toujours. Des stratégies M&E alternatives étaient nécessaires.
Stratégies de surveillance et d'évaluation
L'utilisation d'informations contextuelles liées à la nature de l'instabilité dans les populations des camps a d'abord été considérée pour aider à interpréter les résultats. Cependant, il est souvent difficile de trouver un ensemble complet ou quasi-complet d'informations utiles car les données ne sont pas systématiquement collectées et rapportées, les données ne sont pas partagées entre les partenaires et certaines données sont très difficiles à collecter (par ex. maintenir l'accès aux rations et autres avantages).
L'analyse des données sous forme de séries chronologiques a été jugée utile car elle a permis d'identifier les tendances à long terme et leurs exceptions (comme le montrent les Graphiques 6 et 12). Cependant, cette approche ne fonctionne pas avec une seule enquête ou une paire d'enquêtes, et de grands nombres (c'est-à-dire 20 sondages ou plus) sont habituellement requis. Peu de programmes durent 20 ans ou peuvent fournir 20 ans de données annuelles (un seul endroit sur 248 dans la base de données SENS comptait plus de 20 points de données), ce qui rend cette tâche impossible.
Les méthodes standard pour l'analyse des tendances dans les séries chronologiques supposent des points de données régulièrement espacés, ce qui n'était pas toujours le cas dans les enquêtes de la base de données du HCR. Par exemple, dans un contexte (Ouri Cassoni au Tchad), les données étaient disponibles à partir des enquêtes menées en juillet-août 2008, novembre 2009, octobre-décembre 2010, septembre-novembre 2011, janvier-mars 2013, novembre 2014 et décembre 2015. Les points de données dans cet exemple sont d'environ 16, 12, 11, 16, 21 et 13 mois d'intervalle et il n'y a pas de données pour 2012.
Les méthodes standard pour l'analyse des tendances dans les séries temporelles ne tolèrent pas très bien les « données éparses » (données avec valeurs manquantes), mais dans la base de données SENS la portée des enquêtes change souvent avec le temps.
Les problèmes de brièveté (c'est-à-dire quelques points de données), d'irrégularité et de parcimonie sont souvent apparus ensemble. Cela a limité le type d'analyse qui pourrait être effectuée. Même la simple décomposition d’une série temporelle par exemple, en une tendance, basée sur des modèles de déplacement moyen, n’aurait pas pu être possible en raison des composantes saisonnières et des données secondaires créant une interférence (aléatoire)2.
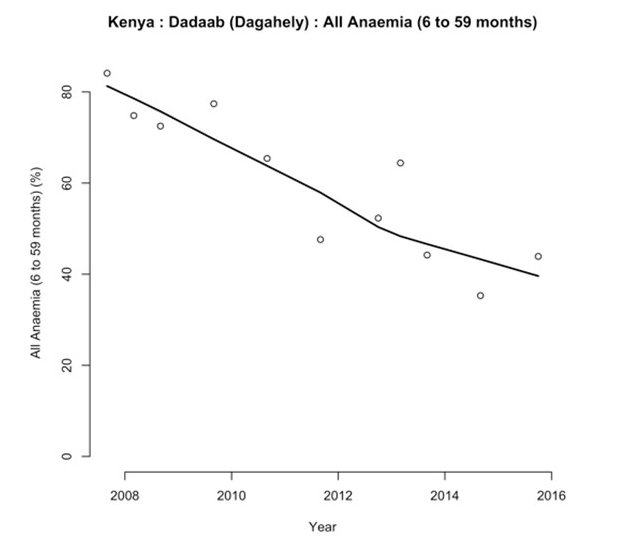
Compte tenu des limitations associées aux données, une procédure d’analyse de données atypique fut employée. Cette procédure est décrite dans la Encadré 1 et la Encadré 2. Cette procédure s’attaque aux problèmes avec la base de données sommaire SENS (tirant ses données par exemple d’échantillons de dimensions véritables plutôt que de dimensions optimales) et a permis d’obtenir des limites de lignes de tendances fiables à 95 pour cent. Une analyse beaucoup plus simple, mais tout aussi utile pourrait être effectuée en ajustant une courbe de LOWESS (moyenne localement pondérée de nuage de points) aux estimations ponctuelles précises des valeurs des indicateurs (voir Image 14). La courbe de LOWESS peut fonctionner à partir de séries temporelles courtes, irrégulières ou sporadiques, mais s’avère peu utile en présence d’une faible quantité de points de données (ex. : ≤ 5). Une autre approche basée sur l’utilisation de données provenant uniquement d’un seul sondage SENS fut mise à l’essai. Dans le cadre de cette approche, il fut assumé que les interventions ou les programmes sont fondés sur des faits véritables et associés à une forte probabilité d’entraîner un changement positif sur la santé des individus couverts et, si fournis avec un haut niveau de couverture, entraîneront des changements considérables au sein de la population.
Encadré 1 : Procédure utilisée afin de travailler avec des données peu nombreuses, irrégulières et sporadiques
Nous procédons à l’analyse des résultats obtenus (résultats dont les valeurs des indicateurs présentent un taux de 95 % de limites de confiance) à partir de la base de données sommaire SENS plutôt qu’à partir des données brutes provenant du sondage.
Le premier point de données contenu dans la base de données sommaire SENS date de 1997. La donnée représentant le temps (t) fut enregistrée en fonction du mois de collecte des données à partir du mois de janvier 1997.
Pour obtenir les données concernant un seul endroit, il faudrait donc utiliser les données associées au temps (t) du premier sondage M&E.
Les estimations représentées par les indicateurs de pair avec les limites de confiances leur étant associées, furent exprimées sous forme de proportions. Les distributions de l’échantillonnage de chaque indicateur en fonction de chaque point de donnée furent recréées à partir de l’estimation représentée par l’indicateur (p) ainsi que les limites de confiance supérieures (UCL) et inférieures (LCL) à 95 % y étant associées (UCL et LCL). La variance fut estimée à :
La taille de l’échantillon optimal (n) fut ensuite estimée à :
Cette procédure vise les problèmes concernant les tailles manquantes et non ajustées des échantillons (afin de permettre la création de représentations graphiques). L’ajustement était préférable en vue de la représentation graphique puisque les échantillons par grappes présentent souvent des échantillons de tailles optimales inférieures au nombre d’enfants comptés dans l’échantillon.
La distribution de l’échantillonnage pour chaque indicateur à chaque mesure de temps fut recréée comme suit :
Les distributions d’échantillonnage recréées furent rééchantillonées à maintes reprises (r = 9999). Une matrice (M1) formée de r rangées (où r représente le nombre de répliques rééchantillonées utilisées) et d’une colonne pour chaque valeur temporelle fut créée. Par exemple :
Une courbe de LOWESS plus douce, possédant une étendue = 1 (l’étendue représentant la somme de toutes les données), ainsi que trois itérations « robustifiantes », furent appliquées à chaque rangée de la matrice M1 afin d’obtenir une seconde matrice (M2). Les cellules de cette seconde matrice détiennent les valeurs de LOWESS lissées de chaque rangée de la matrice M1. Par exemple :
La courbe de tendance est composée des estimations par donnée de temps calculées en tant que sommaires des colonnes de la matrice M2. La courbe de tendance centrale fut calculée comme étant la médiane de chaque colonne de la matrice M2 et les limites de confiance de 95 % associées à la courbe de tendance centrale furent calculées comme étant les 2,5e et 97,5e centiles de chaque colonne de la matrice M2.
Le processus de lissage de LOWESS est décrit dans la Encadre 2.
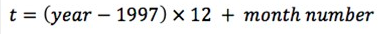
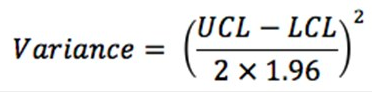
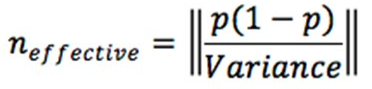
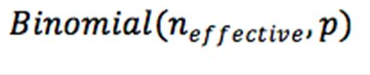


Encadré 2 : Processus de lissage de LOWESS
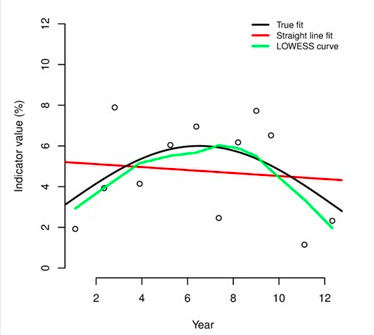
LOWESS (moyenne localement pondérée d’échantillonnage de points) *est une forme d’analyse régressive permettant de tracer une courbe lisse à travers une série temporelle ou un nuage de points afin d’aider à identifier les tendances ou les relations existant entre les variables. Cette méthode s’adapte parfaitement lorsque des données présentant des interférences, des irrégularités ou étant éparses, rendent difficile d’en dégager une tendance. L’exemple ci-dessous montre comment la technique de LOWESS permet de bien identifier une tendance à partir de données ayant été générées par une fonction mathématique (identifié comme étant une « concordance parfaite ») qui présentait initialement de l’interférence et des irrégularités :
Ceci est uniquement dispnible en anglais - désolé pour tout inconvénient causé
La méthode de LOWESS est une méthode non paramétrique permettant de tracer une courbe lisse à partir de nuages de points de données. Dans le cas des méthodes paramétriques, on considère que les données concordent avec une fonction quelconque donnée. Ceci peut mener à l’obtention d’une courbe ou d’une droite de tendance présentant une représentation inadéquate des données (tel qu’il en est le cas dans la « concordance avec une ligne droite » représentée dans l’exemple ci-dessus). Les méthodes de lissage non paramétriques telles que celle de LOWESS cherchent à trouver la courbe qui concorde de la plus juste manière sans considérer que les données doivent concorder avec une fonction particulière. Dans plusieurs situations, les méthodes de lissage non paramétriques constituent un excellent choix. Ceci peut être observé dans l’exemple ci-dessus.
* De nombreux systèmes d’analyse de données offrent des fonctionnalités permettant d’appliquer le lissage de LOWESS. Dans certains systèmes (tel que le SPSS), on le retrouve toutefois sous l’appellation « LOESS ». Microsoft Excel peut effectuer le lissage de LOWESS grâce aux modules d’extension XLSTAT et Peltier Tech Charts pour Excel. Un module d’extension gratuit pour Excel est également offert. La fonctionnalité RobustFit développée par l'University of St. Andrews offre le lissage de LOWESS, tout comme le coffret Dataplot de l'US National Institute for Science and Technology. Les analyses présentées dans cet article furent produites à partir du langage et de l’environnement R pour le calcul statistique.
Le taux d’efficacité fut évalué en fonction des valeurs des indicateurs chez les individus ayant été exposés et chez ceux n’ayant pas été exposés à une intervention. À partir de l’utilisation d’indicateurs de résultats binaires, les ratios de prévalence furent calculés :

Un ratio de prévalence (RP) de moins de 1 indique la possibilité d’un résultat positif (en d’autres termes, l’intervention fut associée à une diminution de la prévalence). Un PR = 1 indique que les résultats ne sont pas associés à l’intervention. Un PR > 1 indique la possibilité d’un résultat négatif (en d’autres termes, l’intervention est associée à une augmentation de la prévalence). Certains problèmes sont associés à cette approche. Lorsque la prévalence est basse (comme c'est souvent le cas en présence de malnutrition aiguë sévère (MAS), d’anémie sévère et d’autres affections sévères), on remarque un très faible nombre de cas associés à l’affection ciblée. Lorsque le niveau de couverture est haut, peu de gens ne seront pas exposés à l’intervention. Une faible prévalence et un haut niveau de couverture considérés conjointement ou séparément diminuent l’importance statistique de l’analyse.
Afin de résoudre ces problèmes, les données brutes (par exemple MUAC et WHZ) ayant servi à la création des indicateurs binaires furent utilisées. Cette approche permet d’obtenir une plus grande puissance statistique puisque les mesures brutes contiennent davantage d’informations que les indicateurs binaires créés pour les représenter. Le problème associé aux faibles nombres de cas fut ainsi éliminé et celui associé aux faibles nombres de cas se retrouvant dans les groupes n’ayant pas été exposés en raison d’un haut niveau de couverture (ou n’ayant pas été couverts) fut ainsi réduit.
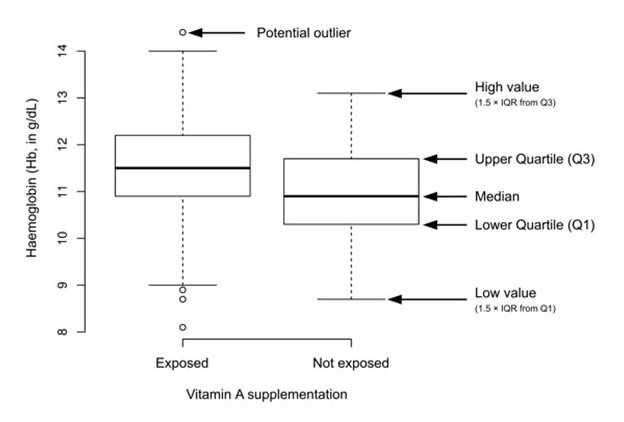
Une analyse visuelle (à partir de boîtes de parcelles) et une analyse statistique (test Kruskal-Wallis basé sur la somme des rangs) furent effectuées afin d’interpréter les résultats. L’Image 15 montre un diagramme en boîtes d’hémoglobine (Hb en g/dL) annoté en fonction du niveau de supplémentation en vitamine A selon les résultats d’un sondage SENS effectué dans le district de Cox Bazaar, au Bangladesh, en mars 2012. Il apparaît donc clairement que les enfants couverts par le programme de supplémentation en vitamine A tendaient à présenter un taux d’hémoglobine plus élevé que celui observé chez les enfants n’ayant pas été couvert par le programme de supplémentation en vitamine A. Le test de Krustal-Wallis basé sur la somme des rangs permet une analyse non paramétrique et unidirectionnelle de la variance sans prendre en compte aucune hypothèse (notamment en lien à la normalité et à la variabilité équivalente) concernant la distribution des données au sein des deux groupes. Pour les données présentées dans l’Image 15, le taux médian d’Hb au sein du groupe couvert était de 11,5 g/dL (on entend par « groupe couvert » les individus recensés ayant reçu une supplémentation en vitamine A au cours des six mois précédents) et de 10,9 g/dL au sein du groupe non couvert (p < 0,0001).
Graphique 14 : Exemple d’un échantillonnage simple de LOWESS
Ceci est uniquement dispnible en anglais - désolé pour tout inconvénient causé
Graphique 15 : Diagramme en boîtes d’hémoglobine associée à une supplémentation en vitamine A
Ceci est uniquement dispnible en anglais - désolé pour tout inconvénient causé
Les deux analyses suggèrent que le programme de supplémentation en vitamine A entraînait des effets positifs quant au taux d’Hb et à la prévalence de l’anémie. Le taux de couverture du programme de supplémentation en vitamine A fut de 91,3 % (IC 95 % = 85,7 % - 96,9 %). Ainsi, il est donc possible de conclure que, bien que des améliorations peuvent encore y être apportées, le programme de supplémentation en vitamine A était offert à raison d’un haut taux de couverture et entraînait probablement des effets positifs sur l’Hb et la prévalence de l’anémie.
Bien que cette approche se révéla utile, elle ne fut pas sans problèmes. Dans les environnements ayant connu un taux de couverture pauvre ou éparse, les effets observés pourraient avoir été engendrés par une couverture ayant été offerte au sein de groupes mieux nantis de la population. Cette approche est également encore vulnérable face à l’instabilité au sein des populations dans les camps. Une découverte négative telle que la corrélation entre le déparasitage et le ratio inférieur de MUAC par exemple, pourrait être causé par l’attribution d’une attention adéquate envers le déparasitage offert aux nouveaux arrivants et l’attribution moindre d’attention envers le déparasitage offert aux résidents déjà sur le camp.
Il est donc important de faire usage de la raison et du sens commun lors de la mise en place de cette approche dans le cadre de mesures ciblées. Par exemple, en effectuant une analyse du MUAC ou du WHZ en fonction de la couverture d’un programme ciblé de supplémentation ou d’alimentation thérapeutique, il serait attendu d’observer un plus faible taux d’état anthropométrique dans les cas couverts puisque les enfants concernés sont sélectionnés précisément en raison du fait qu’ils ont un faible ratio de MUAC ou de WHZ (ou parce qu’ils sont à risque de développer un faible ratio de MUAC ou de WHZ). Cette situation n’est pas problématique dans les cas de mesures d’interventions ciblant des groupes d’âge précis puisque ces programmes sont des programmes « couverture » pour les groupes d’âge visés. Par conséquent, les analyses devraient être limitées aux individus appartenant aux groupes d’âge ciblés.
Conclusions
L’analyse de la base de données issue du sondage SENS ne fut pas aussi déterminante qu’initialement espérée. La simple analyse initiale et finale ne s’avéra pas toujours appropriée en raison de l’instabilité des populations de réfugiés et peut fournir des résultats trompeurs dans le cas des populations instables. Le résultat obtenu est que les interventions en santé publique et en nutrition dans les installations offertes aux réfugiés peuvent entraîner des effets positifs bien que la prévalence demeure élevée. Une prévalence élevée de la MAG et ne semblant jamais régresser ne signifie pas que la santé publique et les programmes nutritionnels sont un échec, mais pourrait plutôt être causée par une ou plusieurs formes d’instabilité au sein de la population. L’observation et le rapport d’efficacité individuelle, tel que dans l’analyse associée à l’Image 15, pourrait s’avérer utile dans de tels contextes.
Dans cette étude, différentes approches d’analyse simple furent proposées pour analyser les données correspondant aux situations des réfugiés afin d’éviter les problèmes décrits. Un travail additionnel est requis afin d’examiner plus en détail ces obstacles et tester, optimiser ou remplacer ces méthodes qui possèdent probablement une grande applicabilité.
Footnotes
1Tous les détails concernant les indicateurs sélectionnés contenus dans la Base de données générale du SENS de l’UNHCR sous la responsabilité du siège social de l’organisme sont disponibles sur demande.
2Les modalités concernant l’emploi de moyennes mobiles et de séries temporelles plus constantes sont détaillées dans les références techniques du FANTA SQUEAC/SLEAC : www.fantaproject.org/monitoring-and-evaluation/squeac-sleac